
Pandas یک کتابخانه منبع باز است که عمدتا برای کار با داده های رابطه ای یا برچسب دار به راحتی و بصری ساخته شده است.
این ساختارها و عملیات مختلف داده را برای دستکاری داده های عددی و سری های زمانی فراهم می کند. این کتابخانه در لایه بالاتر کتابخانه NumPy ساخته شده است. Pandas سریع است و دارای عملکرد و بهره وری بالا برای کاربران است.
تاریخچه
Pandas در ابتدا توسط وس مک کینی در سال ۲۰۰۸ و زمانی که در AQR Capital Management کار می کرد توسعه یافت. وی AQR را متقاعد کرد که به او اجازه دهد Pandas را منبع باز کند. یکی دیگر از کارمندان AQR ، چانگ ش، به عنوان دومین همکاری کننده عمده در کتابخانه در سال ۲۰۱۲ پیوست. با گذشت زمان، نسخه های زیادی از پانداها منتشر شد. آخرین نسخه پانداها ۱.۰.۱ است
مزیت ها
سریع و کارآمد برای دستکاری و تجزیه و تحلیل داده ها.
داده های مختلف اشیا فایل بارگیری می شود.
مدیریت آسان داده های از دست رفته (که به صورت NaN نشان داده می شوند) در داده های نقطه شناور و همچنین نقاط غیر شناور
تغییرپذیری اندازه ستون ها می توانند از DataFrame و اشیا dim بعدی بالاتر حذف شوند
ادغام و پیوستن مجموعه داده ها
تغییر شکل و محوری مجموعه داده ها
قابلیت سری زمانی را فراهم می کند
گروهی با قابلیت برای انجام عملیات تقسیم-اعمال-ترکیب در مجموعه داده ها
نصب pandas
PIP یک سیستم مدیریت بسته است که برای نصب و مدیریت بسته های نرم افزاری / کتابخانه های نوشته شده در پایتون استفاده می شود.
با استفاده از دستور زیر می توانید pandas را با استفاده از PIP نصب کنید:
pip install pandas
شروع کار
پس از نصب pandas در سیستم، باید کتابخانه را وارد کنید. این ماژول به طور کلی به عنوان وارد می شود
import pandas as pd
در اینجا از pd به عنوان مستعار Pandas یاد می شود. با این حال، نیازی به وارد کردن کتابخانه با استفاده از نام مستعار نیست، بلکه فقط به نوشتن مقدار کمتری از کد در هر زمان فراخوانی یک روش یا خاصیت کمک می کند.
پانداها به طور کلی دو ساختار داده برای تغییر داده ها فراهم می کنند:
- Series
- DataFrame
Series
سری Pandas یک آرایه با برچسب یک بعدی است که قادر به نگهداری داده ها از هر نوع (عدد صحیح، رشته، شناور، اشیا پایتون و غیره) است. به برچسب های محور در مجموع شاخص گفته می شود.
سری Pandas چیزی نیست جز ستونی در یک صفحه اکسل. نیازی نیست که برچسب ها منحصر به فرد باشد بلکه باید از نوع غیر قابل تغییر باشد. این شی از نمایه سازی عدد صحیح و بر اساس برچسب پشتیبانی می کند و مجموعه ای از روش ها را برای انجام عملیات مربوط به فهرست فراهم می کند.

ساخت سری
در دنیای واقعی، یک سری Pandas با بارگذاری مجموعه های داده از حافظه موجود ایجاد می شود، فضای ذخیره سازی می تواند پایگاه داده SQL، فایل CSV و فایل اکسل باشد. سری Pandas را می توان از لیست، دیکشنری، و از یک مقیاس اسکالر و غیره ایجاد کرد.
import pandas as pd import numpy as np # Creating empty series ser = pd.Series() print(ser) # simple array data = np.array(['g', 'e', 'e', 'k', 's']) ser = pd.Series(data) print(ser) خروجی
Series([], dtype: float64) ۰ g ۱ e ۲ e ۳ k ۴ s dtype: object
DataFrame
Pandas DataFrame یک ساختار داده ای جداولی دارای ابعاد قابل تغییر و ابعاد دو بعدی با محورهای برچسب خورده (ردیف ها و ستون ها) است. فریم داده یک ساختار داده ای دو بعدی است، یعنی داده ها به صورت جدول در سطرها و ستون ها تراز می شوند. DataFrame از سه مولفه اصلی داده ها، سطرها و ستون ها تشکیل شده است.
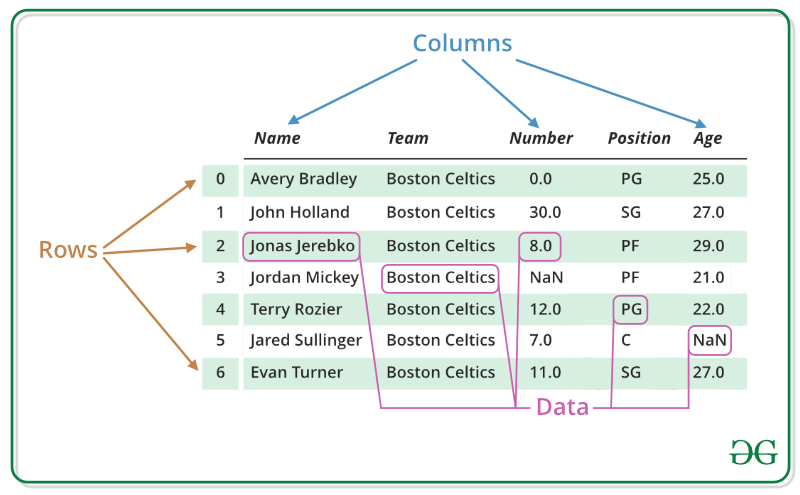
ساخت dataframe
import pandas as pd # Calling DataFrame constructor df = pd.DataFrame() print(df) # list of strings lst = ['Geeks', 'For', 'Geeks', 'is', 'portal', 'for', 'Geeks'] # Calling DataFrame constructor on list df = pd.DataFrame(lst) print(df) خروجی
Empty DataFrame
Columns: []
Index: []
۰
۰ Geeks
۱ For
۲ Geeks
۳ is
۴ portal
۵ for
۶ Geeks
چرا از Pandas برای Data Science استفاده می شود
از pandas به طور کلی برای علم داده استفاده می شود اما چرا؟
دلیل این امر آنست که از pandas همراه با کتابخانه های دیگری که برای علم داده هستند استفاده می شود. این کتابخانه در سطح بالاتر کتابخانه NumPy ساخته شده است به این معنی که بسیاری از ساختارهای NumPy در Pandas استفاده یا تکثیر می شود. داده های تولید شده توسط Pandas اغلب به عنوان ورودی برای رسم توابع Matplotlib، تجزیه و تحلیل آماری در SciPy، الگوریتم یادگیری ماشین در Scikit-learn استفاده می شود.
برنامه Pandas را می توان از هر ویرایشگر متنی اجرا کرد اما توصیه می شود برای این از Jupyter Notebook استفاده کنید زیرا Jupyter با توجه به توانایی اجرای کد در یک سلول خاص به جای اجرای کل فایل، به Jupyter اجازه می دهد. Jupyter همچنین راهی آسان برای تجسم چارچوب داده ها و نمودارهای pandas فراهم می کند.
مطالب پیشنهادی برای شما
- معرفی فریمورک Kivy در پایتون (بخش یک)
- معرفی کتابخانه NumPy در پایتون
- آموزش رابط گرافیکی Tkinter (بخش اول)
- تولید رمز تصادفی با پایتون
- ضبط صدا با استفاده از پایتون
- معرفی کتابخانه Bokeh در پایتون
- کار با فایل های اکسل (بخش اول)

از سال ۸۸ وارد دنیای الکترونیک و فناوری اطلاعات شدم و در زمینه مشاوره، طراحی و ساخت پروژههای سختافزاری فعالیت میکنم.
تجربه برنامه نویسی به زبان های پایتون و سی و همچنین کار با انواع میکروکنترلرها و بردهای سخت افزاری را دارم.
- نرم افزار آموزش پیانو - تیر ۲۴, ۱۴۰۴
- NAT، امنیت شبکههای IPv4 و IPv6 و بررسی IPsec - تیر ۱۳, ۱۴۰۴
- نرم افزار مانیتورینگ شبکه - خرداد ۱۴, ۱۴۰۴