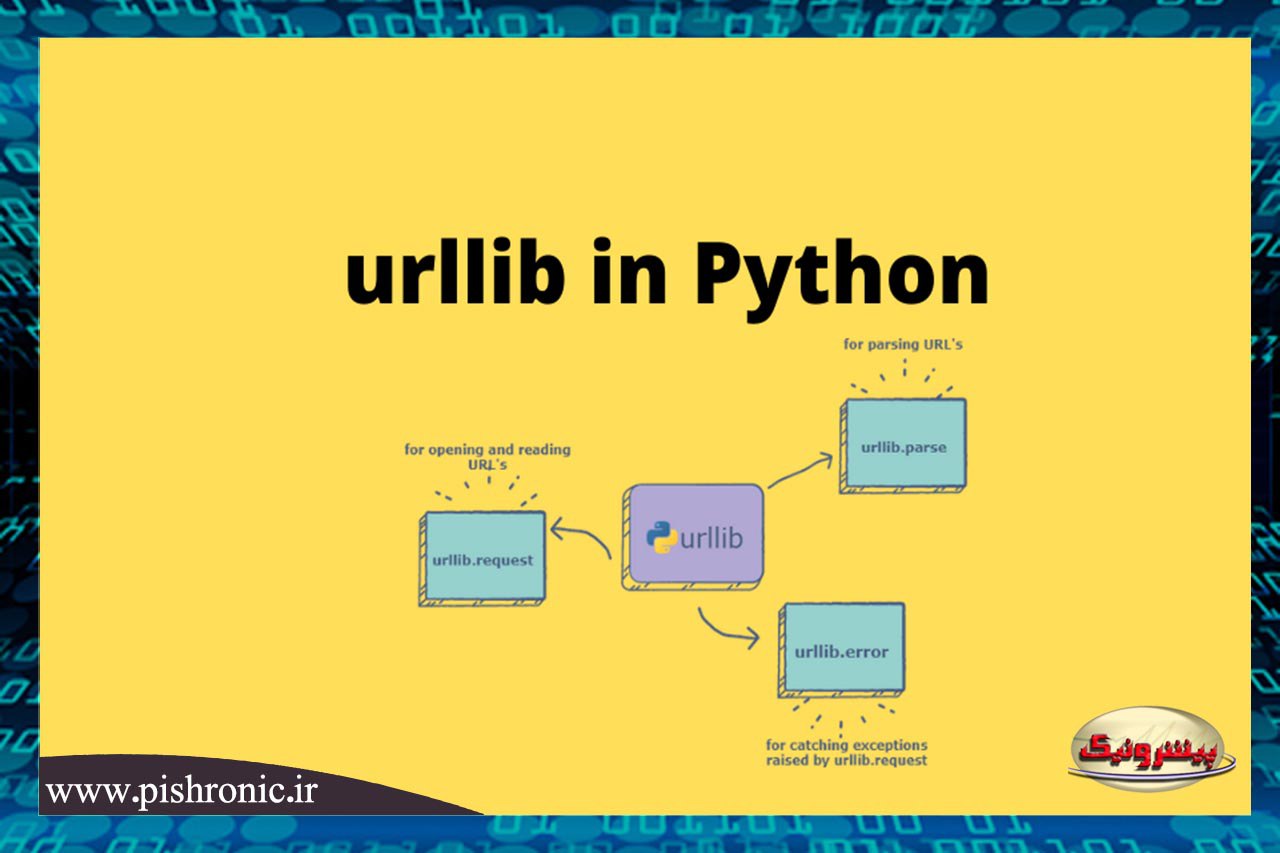
ماژول urllib ماژول مدیریت URL برای پایتون است. برای واکشی URL ها (Uniform Resource Locators) استفاده می شود.
این ماژول از عملکرد urlopen استفاده می کند و می تواند با استفاده از انواع مختلف پروتکل ها URL ها را واکشی کند.
Urllib بسته ای است که چندین ماژول برای کار با URL ها را جمع آوری می کند
مانند:
urllib.request : برای باز کردن و خواندن
urllib.parse : برای تجزیه URL ها
urllib.error : استثناهای مطرح شده
urllib.robotparser : برای تجزیه فایلهای robot.txt
توجه کنید که اگر urllib در محیط شما وجود ندارد، کد زیر را برای نصب آن اجرا کنید.
pip install urllib
این ماژول به تعریف توابع و کلاسها برای باز کردن URL ها (بیشتر HTTP) کمک می کند.
یکی از ساده ترین راه ها برای باز کردن چنین URL هایی این است:
urllib.quest.urlopen (url)
این مورد را می توانیم در یک مثال مشاهده کنیم:
import urllib.request
request_url = urllib.request.urlopen('https://www.www.pishronic.ir/')
print(request_url.read())
urllib.parse
این ماژول به تعریف توابع برای دستکاری URL ها و اجزای سازنده آنها، ساخت یا شکستن آنها کمک می کند و تمرکز معمولاً بر تقسیم URL به اجزای کوچک است. یا پیوستن اجزای مختلف URL به رشته URL.
می توانیم از کد زیر ببینیم:
from urllib.parse import * parse_url = urlparse('https://www.pishronic.ir / python/')
print(parse_url)
print("\n")
unparse_url = urlunparse(parse_url)
print(unparse_url)
خروجی:
from urllib.parse import * parse_url = urlparse('https://www.pishronic.ir / python/')
print(parse_url)
print("\n")
unparse_url = urlunparse(parse_url)
print(unparse_url)
توجه: اجزای مختلف یک URL از هم جدا شده و دوباره به هم متصل می شوند. برای درک بهتر از URL دیگری استفاده کنید.
سایر توابع مختلف urllib.parse عبارتند از:
urllib.parse.urlparse اجزای مختلف URL را جدا می کند
urllib.parse.urlunparse به اجزای مختلف URL بپیوندید
urllib.parse.urlsplit شبیه urlparse است اما پارامترها را تقسیم نمی کند
urllib.parse.urlunsplit عنصر tuple برگردانده شده توسط urlsplit را برای ایجاد URL ترکیب می کند.
urllib.parse.urldeflag اگر URL حاوی قطعه باشد، پس از آن URL را برمی گرداند.
urllib.error
این ماژول کلاسهایی را برای استثنا که توسط urllib.quest مطرح شده تعریف می کند. هر زمان در واکشی یک URL خطایی رخ دهد، این ماژول به افزایش موارد استثنا کمک می کند. موارد زیر موارد استثنایی مطرح شده است:
URLError – این خطا برای خطاهای URL یا خطاهای هنگام واکشی URL به دلیل اتصال است و دارای ویژگی “دلیل” است که دلیل خطا را به کاربر می گوید.
HTTPError – این خطا برای خطاهای عجیب HTTP مانند خطاهای درخواست احراز هویت مطرح می شود.
این بخش یک زیر کلاس یا URLError است. خطاهای معمول شامل “۴۰۴” (صفحه یافت نشد)، “۴۰۳” (درخواست ممنوع است) و «۴۰۱» (احراز هویت لازم است).
این موارد را می توانیم در مثال های زیر ببینیم:
# URL Error
import urllib.request
import urllib.parse
# trying to read the URL but with no internet connectivity
try:
x = urllib.request.urlopen('https://www.google.com')
print(x.read())
# Catching the exception generated
except Exception as e :
print(str(e))
URL Error: urlopen error [Errno 11001] getaddrinfo failed
urllib.robotparser
این ماژول شامل یک کلاس واحد است، RobotFileParser.
این کلاس به این سوال پاسخ می دهد که آیا یک کاربر خاص می تواند URL را که فایلهای robot.txt منتشر کرده است واکشی کند یا خیر.
Robots.txt یک فایل متنی است که مدیران وب برای ایجاد دستورالعمل برای جستجوی صفحات در وب سایت خود به ربات های وب ایجاد می کنند. فایل robot.txt درمورد اینکه چه قسمتهایی از سرور قابل دسترسی نیست، به scraper وب می گوید.
برای مثال
# importing robot parser class
import urllib.robotparser as rb
bot = rb.RobotFileParser()
# checks where the website's robot.txt file reside
x = bot.set_url('https://www.pishronic.ir / robot.txt')
print(x)
# reads the files
y = bot.read()
print(y)
# we can crawl the main site
z = bot.can_fetch('*', 'https://www.pishronic.ir/')
print(z)
# but can not crawl the disallowed url
w = bot.can_fetch('*', 'www.pishronic.ir / wp-admin/')
print(w)
None None True False

از سال ۸۸ وارد دنیای الکترونیک و فناوری اطلاعات شدم و در زمینه مشاوره، طراحی و ساخت پروژههای سختافزاری فعالیت میکنم.
تجربه برنامه نویسی به زبان های پایتون و سی و همچنین کار با انواع میکروکنترلرها و بردهای سخت افزاری را دارم.
- نرم افزار آموزش پیانو - تیر ۲۴, ۱۴۰۴
- NAT، امنیت شبکههای IPv4 و IPv6 و بررسی IPsec - تیر ۱۳, ۱۴۰۴
- نرم افزار مانیتورینگ شبکه - خرداد ۱۴, ۱۴۰۴